【Terraform】Cost & Usage ReportをAthenaで分析する
AWSのコスト分析には通常、Cost Explorer が利用されますが、複数のAWSアカウントを調査する際には各アカウントにログインする必要があります。 そこで、この記事では Cost and Usage Report(以下:CUR)のデータを S3 に保存し、Athena で分析する仕組みを作成します。
仕事では Terraform を使用することが多いため、本記事では Terraform で設定します。
今回作成するサービスとアーキテクチャ

通常 CUR のデータを Athena を使って分析したい場合、以下のドキュメントやブログを参考にすれば、Cloud Formation で分析する仕組みを作成できます。
- Amazon Athena を使用したコストと使用状況レポートのクエリ - AWS Documentation
- Querying your AWS Cost and Usage Report using Amazon Athena - AWS Blog
Cloud Formation で作成できるアーキテクチャ

ブログは 2019 年に発表されており、Glue クローラーのクローリングの設定は Crawl all sub-folders (すべてのサブフォルダをクローリング)になっています。
2021 年 10 月から AWS Glue のクローラーが Amazon S3 イベント通知をサポートされ、さらに以下のブログやニュースを読むと、2022 年 10 月に増分クローリングが発表されたことにより、クロール時間とクローラーの実行に必要なデータ処理ユニット(DPU)を削減する方法が紹介されています。
- AWS Glue クローラーは既存の AWS Glue データカタログテーブルでの増分 Amazon S3 クローリングをサポート - AWS whats new
- Build incremental crawls of data lakes with existing Glue catalog tables - AWS Blog
これらの仕組みを Terraform で実現している記事が見当たらなかったので、コードと一緒に記事を書くことにしました。
この記事では、ステップ・バイ・ステップでリソースを作成するため、Terraform のリソースはすべて main.tf ファイルに書いていきます。
| バージョン | |
|---|---|
| Terraform | 1.5.2 |
最終的に完成したコード(リファクタバージョン)は以下の GitHub に置いておきます。
https://github.com/kntks/blog-code/tree/main/2023/07/terraform-cur-athena
$ tree.├── README.md├── backend.tf├── main.tf└── providers.tfterraform { required_version = "~> 1.5.2"
required_providers { aws = { source = "hashicorp/aws" version = "~> 5.7.0" } }}
provider "aws" { region = "ap-northeast-1"}terraform { backend "local" { path = "./terraform.tfstate" }}$ terraform initCUR の配信設定
Section titled “CUR の配信設定”S3 バケットを作成する
Section titled “S3 バケットを作成する”CUR のレポート配信先となる S3 バケットに必要な設定を確認してみます。
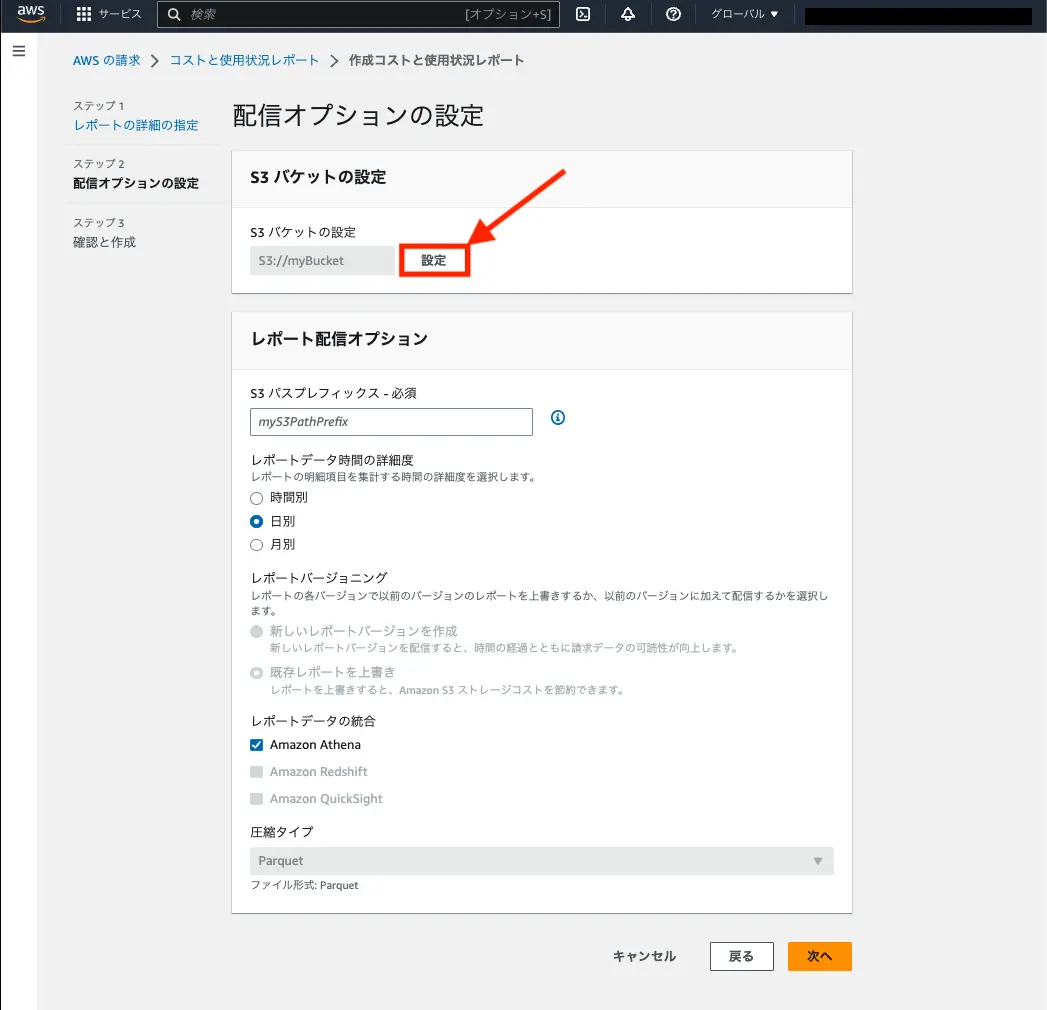 このときバケットを新規に作成するか、既存のバケットかを選択できます。
どちらかを選択しても、バケットポリシーを表示してもらえます。
このときバケットを新規に作成するか、既存のバケットかを選択できます。
どちらかを選択しても、バケットポリシーを表示してもらえます。
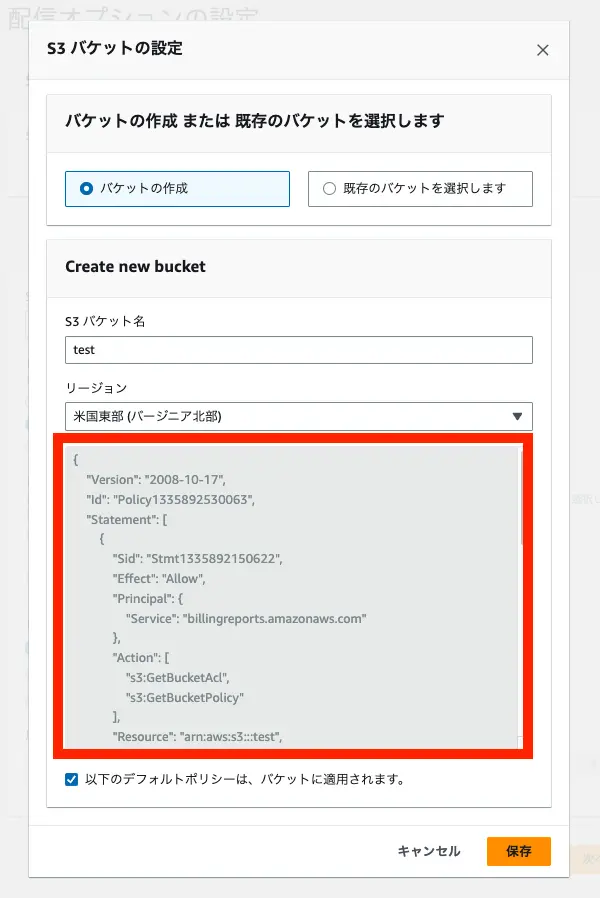
バケットポリシーもわかったので、Terraform で S3 を作成します。
※いくつか値は伏せています。
バケットポリシー
```json { "Version": "2008-10-17", "Id": "Policy1335892530063", "Statement": [ { "Sid": "Stmt1335892150622", "Effect": "Allow", "Principal": { "Service": "billingreports.amazonaws.com" }, "Action": [ "s3:GetBucketAcl", "s3:GetBucketPolicy" ], "Resource": "arn:aws:s3:::(レポート名)", "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:cur:us-east-1:(AWSアカウントID):definition/*", "aws:SourceAccount": "(AWSアカウントID)" } } }, { "Sid": "Stmt1335892526596", "Effect": "Allow", "Principal": { "Service": "billingreports.amazonaws.com" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::(レポート名)/*", "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:cur:us-east-1:(AWSアカウントID):definition/*", "aws:SourceAccount": "(AWSアカウントID)" } } } ] } ```main.tf
data "aws_caller_identity" "current" {}data "aws_region" "current" {}
locals { s3_bucket_name = "example-cur-report" account_id = data.aws_caller_identity.current.account_id}
resource "aws_s3_bucket" "cur" { bucket = local.s3_bucket_name force_destroy = true}
resource "aws_s3_bucket_policy" "cur" { bucket = aws_s3_bucket.cur.id policy = data.aws_iam_policy_document.s3_cur.json}
data "aws_iam_policy_document" "s3_cur" { statement { principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = [ "s3:GetBucketAcl", "s3:GetBucketPolicy", ] resources = [aws_s3_bucket.cur.arn] condition { test = "StringEquals" variable = "aws:SourceArn" values = ["arn:aws:cur:us-east-1:${local.account_id}:definition/*"] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = ["${local.account_id}"] } }
statement { principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = ["s3:PutObject"] resources = ["${aws_s3_bucket.cur.arn}/*"] condition { test = "StringEquals" variable = "aws:SourceArn" values = ["arn:aws:cur:us-east-1:${local.account_id}:definition/*"] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = ["${local.account_id}"] } }}$ terraform plan$ terraform apply -auto-approveCURを作成する
Section titled “CURを作成する”先ほど、S3 を作成しました。次に CUR を設定します。
AWSのリソースは基本 ap-northeast-1 に作成しますが、 CUR は us-east-1 に作成します。
Terraform でこういったケースでは Multiple Provider Configurations を利用するとリージョンを CUR のみ us-east-1 にできます。
providerを追加します。
...
provider "aws" { region = "ap-northeast-1"}
provider "aws" { alias = "virginia" region = "us-east-1"}...
resource "aws_cur_report_definition" "cur_report" { provider = aws.virginia # CURはバージニア北部しかない
report_name = "example-cur-report" time_unit = "HOURLY" format = "Parquet" # "Parquetに設定するなら"compression"も必ず"Perquet" compression = "Parquet" additional_schema_elements = ["RESOURCES"] s3_bucket = local.s3_bucket_name s3_prefix = "billing" s3_region = aws_s3_bucket.cur.region additional_artifacts = ["ATHENA"] # ここがATHENAである場合、他のartifactsは設定できない report_versioning = "OVERWRITE_REPORT" # additional_artifacts = "ATHENA"である場合、ここは必ず"OVERWRITE_REPORT"
depends_on = [ aws_s3_bucket_policy.cur, ]}Resource: aws_cur_report_definition - registry.terraform.io
$ terraform plan$ terraform apply -auto-approveこれで CUR のデータが配信されると S3 バケットの <bucket-name>/<s3_prefix>/<report-name>/<report-name>/year=20xx/month=x/xxxx.parquet ができます。
ちなみに”背景”でお伝えしたCloud Formation のファイルは <bucket-name>/<s3_prefix>/<report-name>/crawler-cfn.yml です。
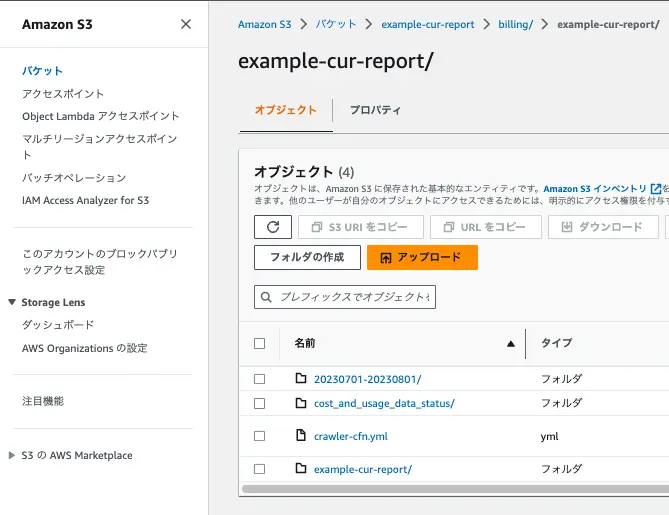
Glue データカタログとクローラー
Section titled “Glue データカタログとクローラー”Glueのデータベースを作成する
Section titled “Glueのデータベースを作成する”ここでは以下のリソースを作成します。
- Glue Catalog database
- Athena workgroup
まず Glue データベースを作成します。
以下を追記します。
...
locals { catalog_db_name = "example_report"}
resource "aws_glue_catalog_database" "cur" { name = local.catalog_db_name create_table_default_permission { permissions = ["ALL"]
principal { data_lake_principal_identifier = "IAM_ALLOWED_PRINCIPALS" } }}Resource: aws_glue_catalog_database
(オプション) ワークグループを作成する
Section titled “(オプション) ワークグループを作成する”必要に応じてワークグループを作成してください。
ワークグループを作成するとクエリ実行の画面右上でワークグループを切り替えることができるようになります。
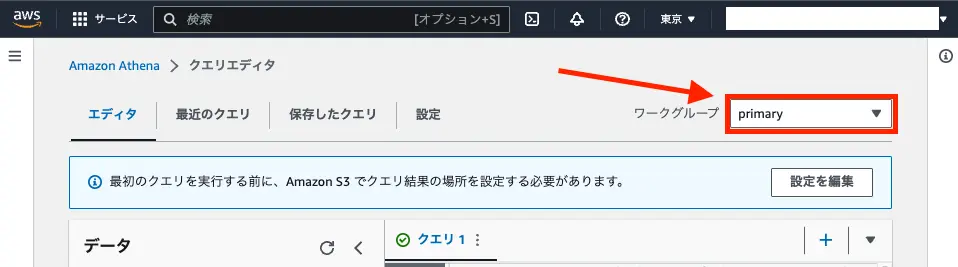
resource "aws_athena_workgroup" "cur" { name = "example"
force_destroy = true configuration { publish_cloudwatch_metrics_enabled = false result_configuration { output_location = "s3://${aws_s3_bucket.cur.id}/query_log" } }}Resource: aws_athena_workgroup - registry.terraform.io
クローラーを作成する
Section titled “クローラーを作成する”クローラーを作成します。
クローラーには IAM ロールを設定する必要があるため、一緒に作成します。
main.tf
...
resource "aws_glue_crawler" "cur" { database_name = aws_glue_catalog_database.cur.name name = "example-cur-crawler" role = aws_iam_role.glue_crawler.arn tags = {} lake_formation_configuration { use_lake_formation_credentials = false } lineage_configuration { crawler_lineage_settings = "DISABLE" } recrawl_policy { recrawl_behavior = "CRAWL_EVERYTHING" }
s3_target { path = "s3://${aws_s3_bucket.cur.bucket}/billing/example-cur-report/example-cur-report" exclusions = [ "**.json", "**.yml", "**.sql", "**.csv", "**.gz", "**.zip" ] } schema_change_policy { update_behavior = "UPDATE_IN_DATABASE" delete_behavior = "DELETE_FROM_DATABASE" }}
resource "aws_iam_role" "glue_crawler" { name = "exampleCURAthenaCrawler" managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"] assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = "sts:AssumeRole" Effect = "Allow" Sid = "" Principal = { Service = "glue.amazonaws.com" } }, ] })}
resource "aws_iam_role_policy" "cur_crawler" { name = "AWSCURCrawlerComponentFunction" role = aws_iam_role.glue_crawler.id
policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ] Effect = "Allow" Resource = "arn:aws:logs:*:*:*" }, { Action = [ "glue:UpdateDatabase", "glue:UpdatePartition", "glue:CreateTable", "glue:UpdateTable", "glue:ImportCatalogToGlue" ] Effect = "Allow" Resource = "*" }, { Action = [ "s3:GetObject", "s3:PutObject" ] Effect = "Allow" Resource = "arn:aws:s3:::${aws_s3_bucket.cur.bucket}/billing/example-cur-report/example-cur-report*" } ] })}
resource "aws_iam_role_policy" "kms_decryption" { name = "AWSCURKMSDecryption" role = aws_iam_role.glue_crawler.id
policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "kms:Decrypt" ] Effect = "Allow" Resource = "*" } ] })}$ terraform plan$ terraform apply -auto-approveterraform apply を実行すると、IAM ロールは以下のようになります。
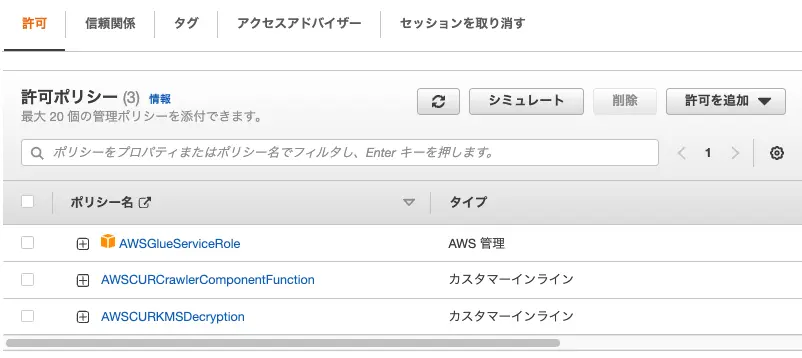
クローラーを実行してみる
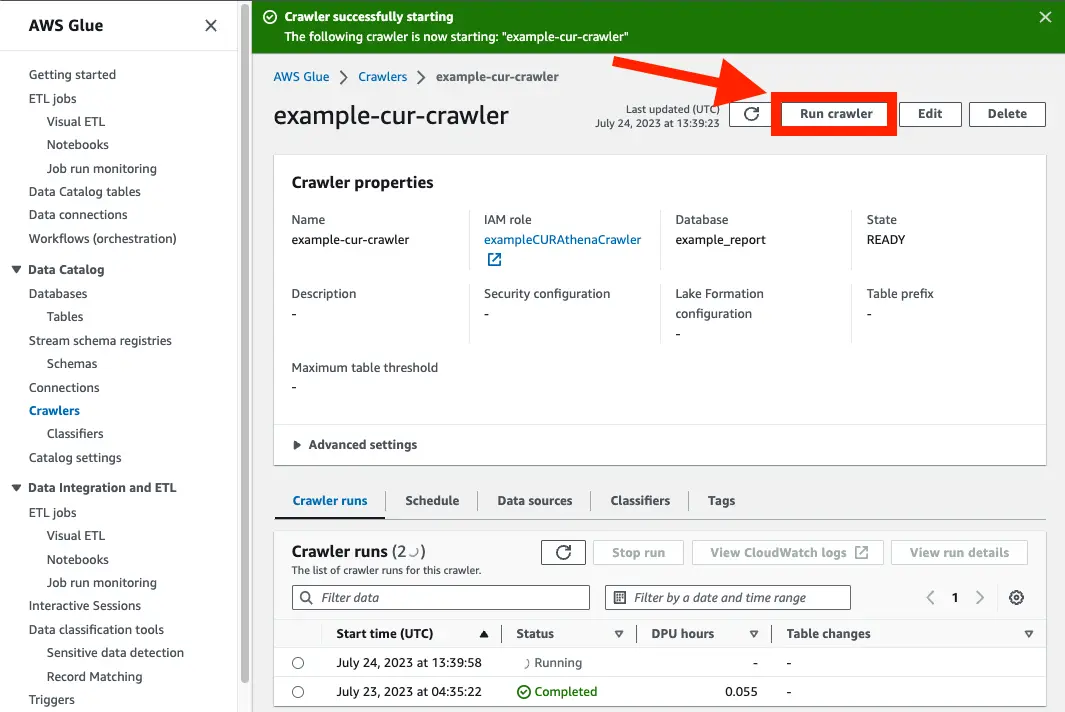
Section titled “クローラーを実行してみる”手動でクローラーを実行してみます。 ドキュメント通りならテーブルが作成されるはずです。
クローラーは 1 回の実行で複数のデータストアをクロールできます。完了すると、クローラーはデータカタログで 1 つ以上のテーブルを作成または更新します
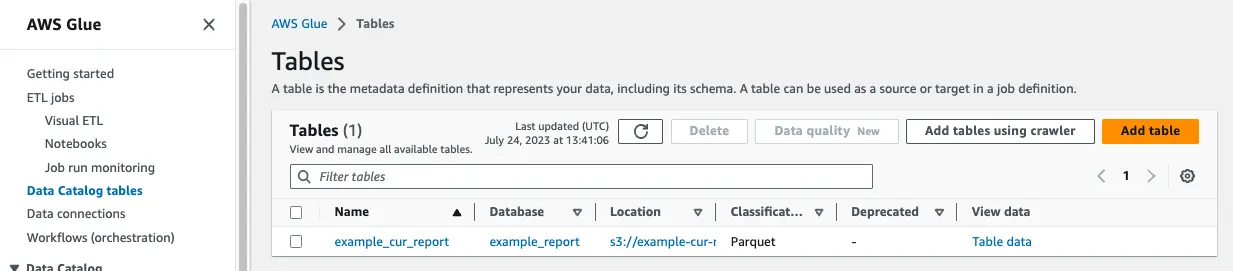
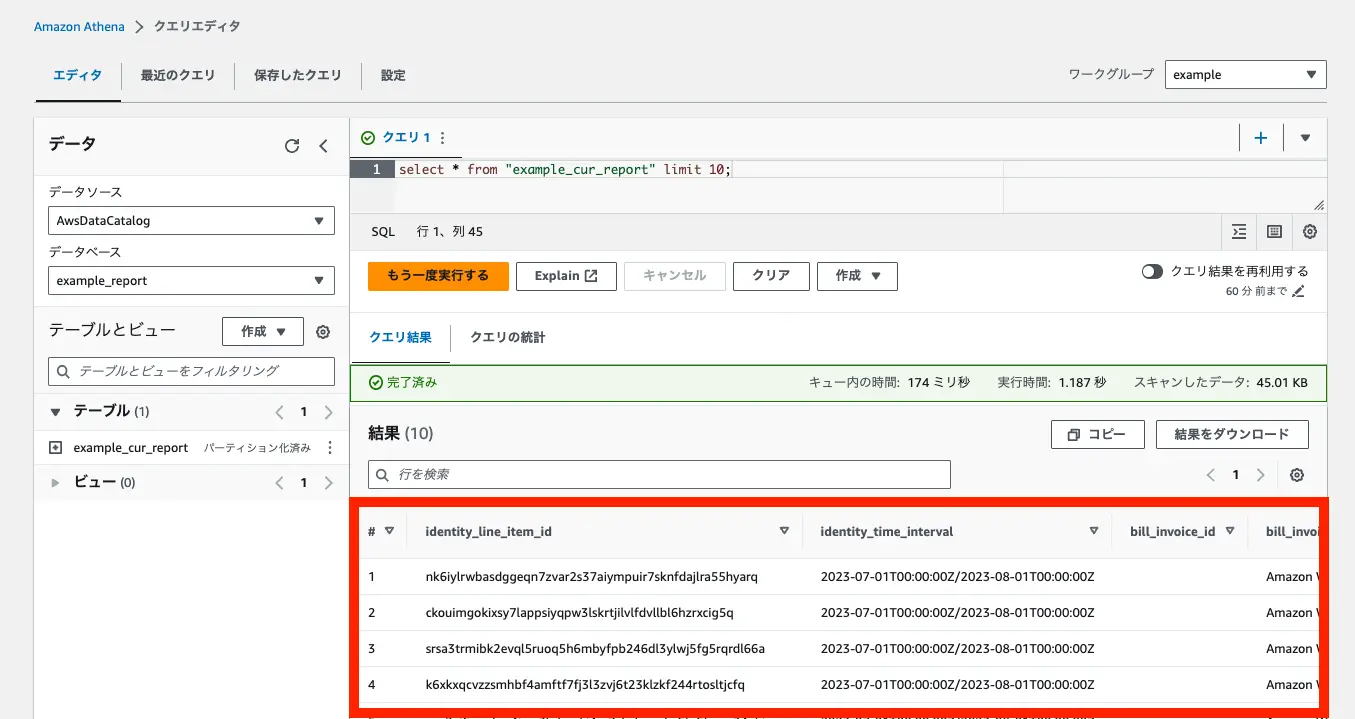
成功後、Glue と Athena のページでテーブルを確認できました。
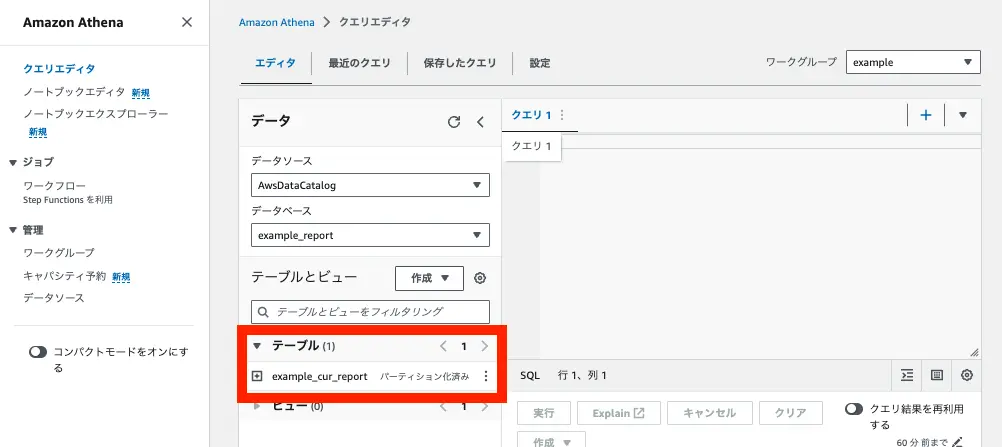
試しにクエリを実行してみると、データをとれていそうです。
データカタログの自動更新設定
Section titled “データカタログの自動更新設定”S3のPutイベントでクローラーを起動する
Section titled “S3のPutイベントでクローラーを起動する”先ほどクローラーを手動実行することで、Athena からデータを確認することができました。
しかし、これでは最新の情報を取得することができません。
定期実行でクローラーが起動されるようにします。
ここからは S3 のイベント通知を利用して、クローラーを実行できるように設定します。
SQSのキューとデッドレターキューを作成し、クローラーが S3 イベントによって起動するように設定を変更します。
main.tf
resource "aws_glue_crawler" "cur" { ... recrawl_policy { recrawl_behavior = "CRAWL_EVERYTHING" recrawl_behavior = "CRAWL_EVENT_MODE" }
s3_target { path = "s3://${aws_s3_bucket.cur.bucket}/billing/kono-test-report/kono-test-report" exclusions = [ ] event_queue_arn = aws_sqs_queue.s3_event.arn dlq_event_queue_arn = aws_sqs_queue.s3_event_deadletter.arn } ...
depends_on = [aws_sqs_queue.s3_event, aws_sqs_queue.s3_event_deadletter]}
...
locals { s3_event_queue_name = "s3-notification-event-queue"}
resource "aws_sqs_queue" "s3_event" { name = "s3-notification-event-queue" delay_seconds = 90 max_message_size = 2048 message_retention_seconds = 86400 receive_wait_time_seconds = 10 redrive_policy = jsonencode({ deadLetterTargetArn = aws_sqs_queue.s3_event_deadletter.arn maxReceiveCount = 4 })}
resource "aws_sqs_queue" "s3_event_deadletter" { name = "s3-event-deadletter-queue" redrive_allow_policy = jsonencode({ redrivePermission = "byQueue", sourceQueueArns = [ "arn:aws:sqs:${data.aws_region.current.name}:${local.account_id}:${local.s3_event_queue_name}" ] })}$ terraform plan$ terraform apply -auto-approve参考:https://github.com/hashicorp/terraform-provider-aws/issues/22577#issuecomment-1086122047
設定完了したらマネジメントコンソールから設定を確認してみます。
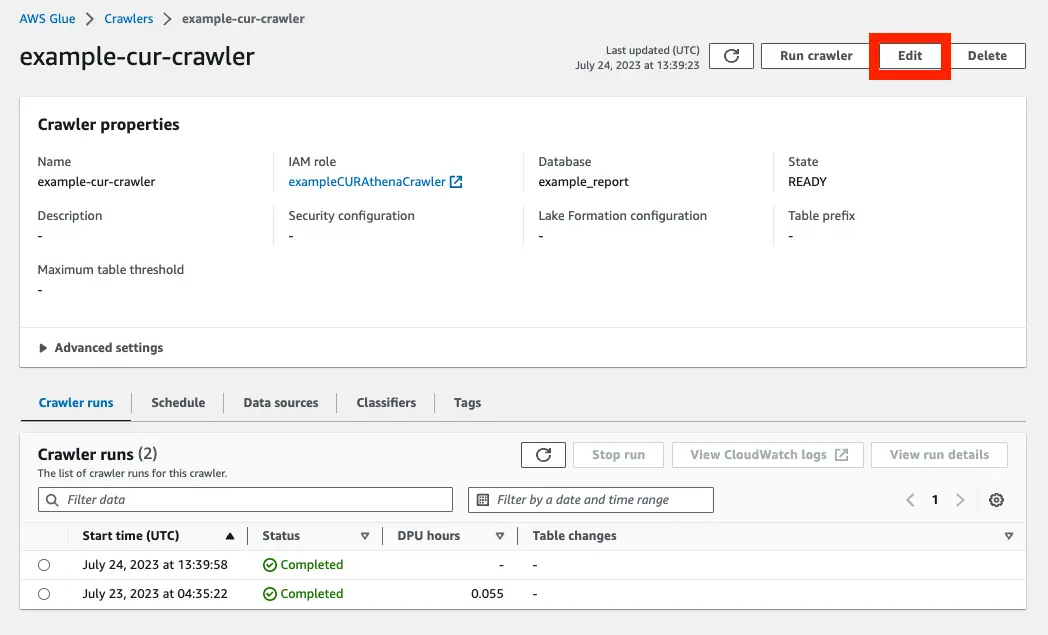
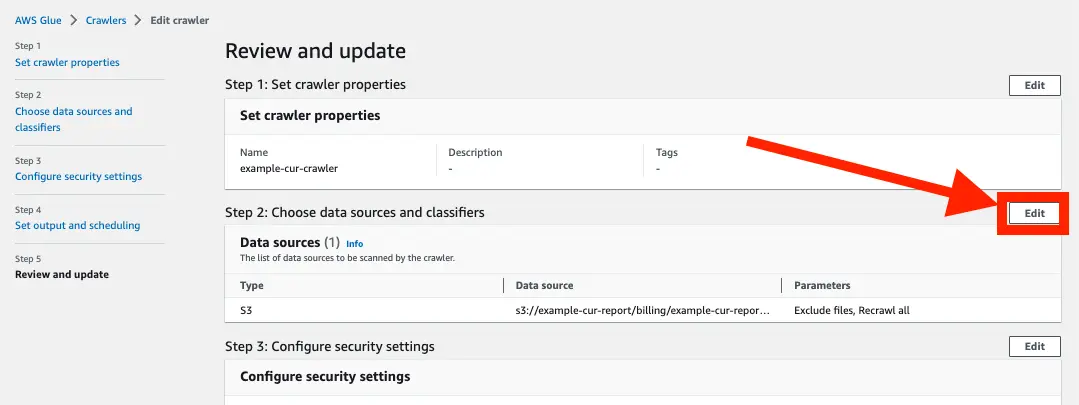
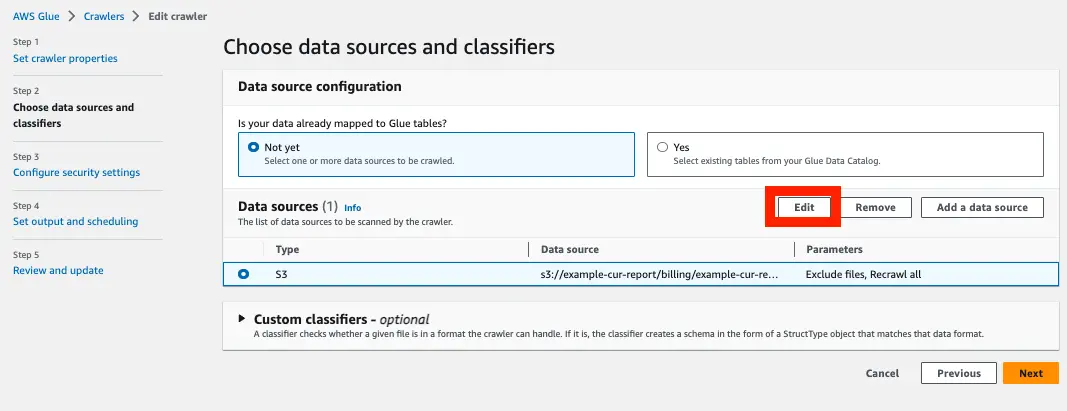
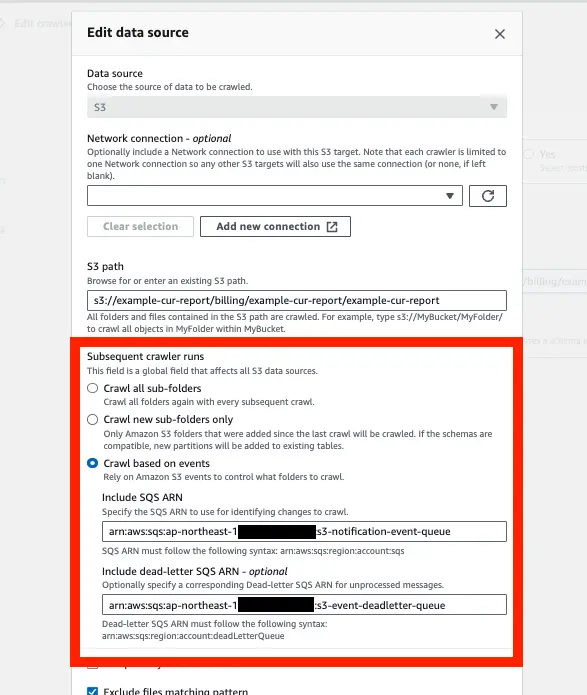
Subsequent crawler runs の項目が Crawl based on events になっています。
SQS も設定されていることが確認できます。
S3 にイベント通知を設定する
Section titled “S3 にイベント通知を設定する”最後に S3 のイベント通知を SQS に送信できるように設定します。
SQS にはキューにアクセスできるポリシーを設定する必要があるので、ポリシーを作成し、キューに設定します。
resource "aws_iam_role_policy" "cur_crawler" { name = "AWSCURCrawlerComponentFunction" role = aws_iam_role.glue_crawler.id
policy = jsonencode({ Version = "2012-10-17" Statement = [ { ... }, { "Effect" : "Allow", "Action" : [ "sqs:DeleteMessage", "sqs:GetQueueUrl", "sqs:ListDeadLetterSourceQueues", "sqs:DeleteMessageBatch", "sqs:ReceiveMessage", "sqs:GetQueueAttributes", "sqs:ListQueueTags", "sqs:SetQueueAttributes", "sqs:PurgeQueue" ], "Resource" : "*" } ] })}
...
resource "aws_sqs_queue" "s3_event" { ...+ policy = data.aws_iam_policy_document.s3_event.json}
...
data "aws_iam_policy_document" "s3_event" { statement { effect = "Allow"
principals { type = "Service" identifiers = ["s3.amazonaws.com"] }
actions = ["sqs:SendMessage"] resources = ["arn:aws:sqs:*:*:${local.s3_event_queue_name}"]
condition { test = "ArnEquals" variable = "aws:SourceArn" values = [aws_s3_bucket.cur.arn] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = [local.account_id] } }}
resource "aws_s3_bucket_notification" "cur" { bucket = aws_s3_bucket.cur.id
queue { queue_arn = aws_sqs_queue.s3_event.arn events = ["s3:ObjectCreated:*"] filter_suffix = ".parquet" }}Resource: aws_s3_bucket_notification
$ terraform plan$ terraform apply -auto-approves3 バケットのプロパティをクリックします。
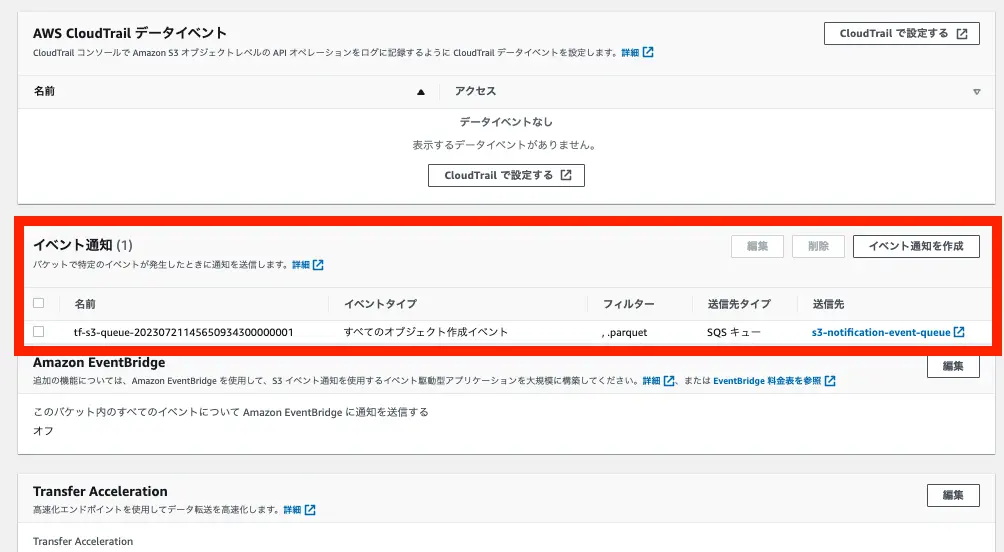
ページを下にスクロールするとイベント通知の設定を見ることができます。
参考:
- Amazon S3 イベント通知 - AWS Documentation
- ステップ 1: Amazon SQS キューを作成する - AWS Documentation
- Amazon S3 イベント通知を使用した加速クロール - AWS Documentation
クローラーを定期実行させる
Section titled “クローラーを定期実行させる”クローラーがすべてのファイルをクローリングするなら、クローリングの間隔を短くすればするほどコストがかかるはずです。
しかし、今回はAmazon S3 イベント通知を使用した加速クロールを利用し、クロールコストが削減されるようにしたのでクローリングの間隔は短くても問題なさそうです。
今回は、3 時間に 1 回定期実行しようと思います。以下の設定では、午前 0時から3時間毎に実行します。
resource "aws_glue_crawler" "cur" { database_name = aws_glue_catalog_database.cur.name schedule = "cron(0 0/3 * * ? *)" name = "example-cur-crawler" role = aws_iam_role.glue_crawler.arn tags = local.tags ...}これで完成です。
$ terraform plan$ terraform apply -auto-approve最後にS3にオブジェクトが作成されたらクローラーが動作するのか確認します。(すでに CUR が配信されており、S3 にデータがあるとします。)
S3 イベント作成後、手動で実行する
Section titled “S3 イベント作成後、手動で実行する”動作確認方法
- S3 から CUR のデータをダウンロードする
- S3 から CUR のデータを削除する
- 削除したデータが存在していたディレクトリに、ダウンロードしたデータをアップロードする
SQS にメッセージが入っていることを確認できます。
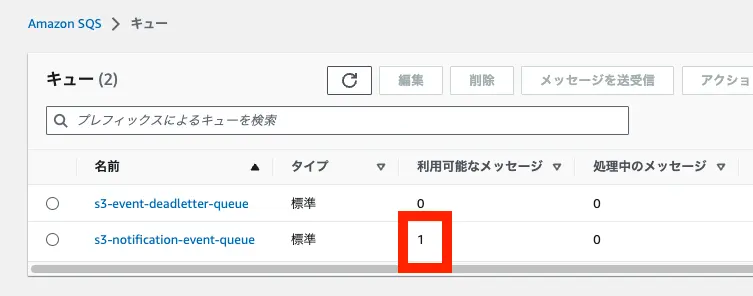
手動でクローラーを実行すると、問題なく実行されました。
SQS にデータがない状態で、クローラーを手動で実行する
Section titled “SQS にデータがない状態で、クローラーを手動で実行する”SQS にデータがない状態で手動実行してみると、Status = Stopped になりました。
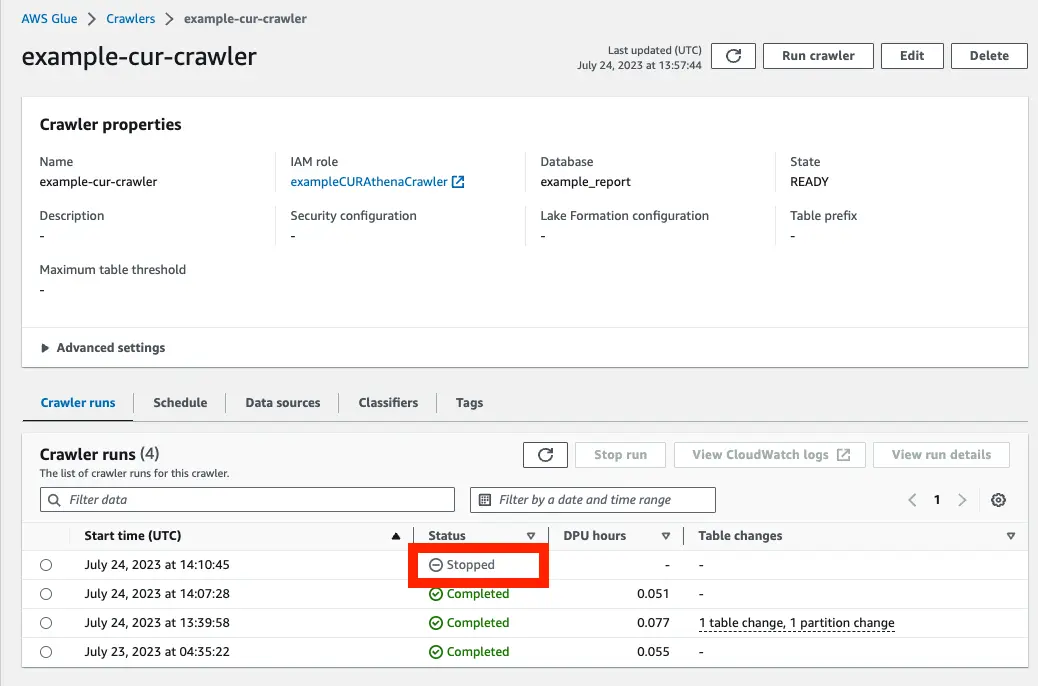
ドキュメント通り、キューにイベントがない場合は、実行されませんでした。
Amazon S3 イベントクロールは、クローラーのスケジュールに基づいて SQS キューから Amazon S3 イベントを使うことで実行します。キューにイベントがない場合、費用はかかりません
作成したファイルはこんな感じです。実装の参考になれば幸いです。
main.tf
data "aws_caller_identity" "current" {}data "aws_region" "current" {}
locals { s3_bucket_name = "example-cur-report" account_id = data.aws_caller_identity.current.account_id}
resource "aws_s3_bucket" "cur" { bucket = local.s3_bucket_name force_destroy = true}
resource "aws_s3_bucket_policy" "cur" { bucket = aws_s3_bucket.cur.id policy = data.aws_iam_policy_document.s3_cur.json}
data "aws_iam_policy_document" "s3_cur" { statement { principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = [ "s3:GetBucketAcl", "s3:GetBucketPolicy", ] resources = [aws_s3_bucket.cur.arn] condition { test = "StringEquals" variable = "aws:SourceArn" values = ["arn:aws:cur:us-east-1:${local.account_id}:definition/*"] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = ["${local.account_id}"] } }
statement { principals { type = "Service" identifiers = ["billingreports.amazonaws.com"] } actions = ["s3:PutObject"] resources = ["${aws_s3_bucket.cur.arn}/*"] condition { test = "StringEquals" variable = "aws:SourceArn" values = ["arn:aws:cur:us-east-1:${local.account_id}:definition/*"] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = ["${local.account_id}"] } }}
resource "aws_cur_report_definition" "cur_report" { provider = aws.virginia # CURはバージニア北部しかない
report_name = "example-cur-report" time_unit = "HOURLY" format = "Parquet" # "Parquetに設定するなら"compression"も必ず"Perquet" compression = "Parquet" additional_schema_elements = ["RESOURCES"] s3_bucket = local.s3_bucket_name s3_prefix = "billing" s3_region = aws_s3_bucket.cur.region additional_artifacts = ["ATHENA"] # ここがATHENAである場合、他のartifactsは設定できない report_versioning = "OVERWRITE_REPORT" # additional_artifacts = "ATHENA"である場合、ここは必ず"OVERWRITE_REPORT"
depends_on = [ aws_s3_bucket_policy.cur, ]}
# -------------------------------------
locals { catalog_db_name = "example_report"}
resource "aws_glue_catalog_database" "cur" { name = local.catalog_db_name create_table_default_permission { permissions = ["ALL"]
principal { data_lake_principal_identifier = "IAM_ALLOWED_PRINCIPALS" } }}
resource "aws_athena_workgroup" "cur" { name = "example"
force_destroy = true configuration { publish_cloudwatch_metrics_enabled = false result_configuration { output_location = "s3://${aws_s3_bucket.cur.id}/query_log" } }}
# ---------------------------
resource "aws_glue_crawler" "cur" { database_name = aws_glue_catalog_database.cur.name schedule = "cron(0 0/3 * * ? *)" name = "example-cur-crawler" role = aws_iam_role.glue_crawler.arn lake_formation_configuration { use_lake_formation_credentials = false } lineage_configuration { crawler_lineage_settings = "DISABLE" } recrawl_policy { recrawl_behavior = "CRAWL_EVENT_MODE" }
s3_target { path = "s3://${aws_s3_bucket.cur.bucket}/billing/example-cur-report/example-cur-report" exclusions = [ "**.json", "**.yml", "**.sql", "**.csv", "**.gz", "**.zip" ] event_queue_arn = aws_sqs_queue.s3_event.arn dlq_event_queue_arn = aws_sqs_queue.s3_event_deadletter.arn } schema_change_policy { update_behavior = "UPDATE_IN_DATABASE" delete_behavior = "DELETE_FROM_DATABASE" }
depends_on = [aws_sqs_queue.s3_event, aws_sqs_queue.s3_event_deadletter]}
resource "aws_iam_role" "glue_crawler" { name = "exampleCURAthenaCrawler" managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"] assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = "sts:AssumeRole" Effect = "Allow" Sid = "" Principal = { Service = "glue.amazonaws.com" } }, ] })}
resource "aws_iam_role_policy" "cur_crawler" { name = "AWSCURCrawlerComponentFunction" role = aws_iam_role.glue_crawler.id
policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ] Effect = "Allow" Resource = "arn:aws:logs:*:*:*" }, { Action = [ "glue:UpdateDatabase", "glue:UpdatePartition", "glue:CreateTable", "glue:UpdateTable", "glue:ImportCatalogToGlue" ] Effect = "Allow" Resource = "*" }, { Action = [ "s3:GetObject", "s3:PutObject" ] Effect = "Allow" Resource = "arn:aws:s3:::${aws_s3_bucket.cur.bucket}/billing/example-cur-report/example-cur-report*" }, { Action = [ "sqs:DeleteMessage", "sqs:GetQueueUrl", "sqs:ListDeadLetterSourceQueues", "sqs:DeleteMessageBatch", "sqs:ReceiveMessage", "sqs:GetQueueAttributes", "sqs:ListQueueTags", "sqs:SetQueueAttributes", "sqs:PurgeQueue" ], Effect = "Allow", Resource = "*" } ] })}
resource "aws_iam_role_policy" "kms_decryption" { name = "AWSCURKMSDecryption" role = aws_iam_role.glue_crawler.id
policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "kms:Decrypt" ] Effect = "Allow" Resource = "*" } ] })}
# --------------------------
locals { s3_event_queue_name = "s3-notification-event-queue"}
resource "aws_sqs_queue" "s3_event" { name = "s3-notification-event-queue" delay_seconds = 90 max_message_size = 2048 message_retention_seconds = 86400 receive_wait_time_seconds = 10 redrive_policy = jsonencode({ deadLetterTargetArn = aws_sqs_queue.s3_event_deadletter.arn maxReceiveCount = 4 }) policy = data.aws_iam_policy_document.s3_event.json}
resource "aws_sqs_queue" "s3_event_deadletter" { name = "s3-event-deadletter-queue" redrive_allow_policy = jsonencode({ redrivePermission = "byQueue", sourceQueueArns = [ "arn:aws:sqs:${data.aws_region.current.name}:${local.account_id}:${local.s3_event_queue_name}" ] })}
# --------------------------
data "aws_iam_policy_document" "s3_event" { statement { effect = "Allow"
principals { type = "Service" identifiers = ["s3.amazonaws.com"] }
actions = ["sqs:SendMessage"] resources = ["arn:aws:sqs:*:*:${local.s3_event_queue_name}"]
condition { test = "ArnEquals" variable = "aws:SourceArn" values = [aws_s3_bucket.cur.arn] } condition { test = "StringEquals" variable = "aws:SourceAccount" values = [local.account_id] } }}
resource "aws_s3_bucket_notification" "cur" { bucket = aws_s3_bucket.cur.id
queue { queue_arn = aws_sqs_queue.s3_event.arn events = ["s3:ObjectCreated:*"] filter_suffix = ".parquet" }}