Kubernetes上のアプリケーションから繋いでいるDBのマイグレーション方法を考える
Kubernetes 上で運用しているアプリケーションと連携しているデータベースのマイグレーションを効果的に行うためには、どのような手法があるのでしょうか?
この記事では、AWS を使用している場合を想定し、データベースのマイグレーションについていくつかの方法を考えてみます。
そして、現在参画しているプロジェクトでどの方法を選択したか紹介します。
方法を考える前に、筆者が参画している組織の状況を確認します。
- Git はセルフホストの GitLab
- CI はセルフホストの GitLab CI Runner
- 複数のプロジェクトが同じ GitLab と GitLab CI Runnerを使用している
- Kubernetes のマニフェスト管理は helm (helmfile)
- アプリケーションをデプロイするときは helmfile コマンドを実行
- データベースのパスワードなどのシークレット情報は sops + AWS KMS で暗号化し Git で管理している

アプリケーションのデプロイ前にマイグレーションを完了させる
まず方法として以下が考えられます。
- 手元のPCから手動で実行する
- マイグレーション用の EC2インスタンスを立て、ssm 等でログイン後、実行する
- CI で実行する
- Pod の init Containers を使用する
- Kubernetes の Job を使用する
手元の PC から手動で実行する
Section titled “手元の PC から手動で実行する”これは、ローカル開発環境で実行する場合とほぼ同じになるはずです。
使用しているマイグレーションツールの向け先を、マイグレーションしたいデータベースにして実行するだけです。
しかし、この方法だと以下の懸念点があり、却下しました。
- マイグレーションツールのバージョンなど、実行者の環境に左右される可能性がある
- 手元のPCからデータベースにアクセスできるのでセキュリティ的に問題がある
- 開発時にデータベースの向け先に注意しながら、マイグレーションを実行しないといけない
マイグレーション用のEC2インスタンスを立てssm等でログイン後実行する
Section titled “マイグレーション用のEC2インスタンスを立てssm等でログイン後実行する”この方法も1と同じく、マイグレーションは手動で行います。
マイグレーションファイルは Git で管理されています。
そのため、EC2インスタンスが Git からプルできるようにするためには、事前の準備が必要になります。
具体的には、SSHキーの設定やアクセストークンの取得などが必要となるでしょう。
手動かつ EC2インスタンスの管理やコストが増えるのが嫌だったので、この案は却下しました。
CIで実行する
Section titled “CIで実行する”CI 上でのマイグレーション実行は、マイグレーションが成功してからアプリケーションをデプロイする順番を制御できるため、有益な選択肢となります。
ただし、CI 環境からデータベースにアクセスするには、CI がデータベースの接続先URLやパスワードを知っている必要があります。
そのため、以下の IAM ロールが必要となります。
- データベースへのマイグレーションが可能なロール
- 暗号化されたファイルを復号化するために KMS へアクセスできるロール
さらに、CI からアクセスできるようにするために、AssumeRole を設定する必要があります。
結果的に、以下の理由からこのアプローチを却下しました。
- すでに helmfile を使用して、シークレット情報の復号化とデプロイを行う仕組みが存在する
- CI で実行可能にするためにデータベースへのアクセス権限やパスワードの管理に関する考慮事項が必要である
Pod の init Containersを使用する
Section titled “Pod の init Containersを使用する”Pod の Init Containers の仕組みを利用する方法です。
init containers は Pod の準備ができる前に完了する必要があるコンテナなので、マイグレーション後に Pod を起動するという順序を保つことができます。
they must run to completion before the Pod can be ready. Differences from regular containers
しかし、以下の懸念点があったので却下しました。
- init containers を設定した複数の Pod からマイグレートが実行される可能性があるので、競合があった場合にどうなるのかわからない
- マイグレーション実行用のコンテナを作成するため Dockerfile を用意、メンテナンスしていく必要がある
KubernetesのJobを使用する
Section titled “KubernetesのJobを使用する”Kuberentes の Job を利用する方法です。しかし、Job は完了すると Node に残るため、マイグレーションの度に完了した Job が増え続けるという懸念があります。
完了後、自動的に Job を削除方法は以下の3つを方法があります。
- Argo CD の hook を利用する
.spec.ttlSecondsAfterFinishedを設定して Jobが完了後、自動的に Job を削除する- helm の hook を利用する
Argo CD の hook を利用する
Section titled “Argo CD の hook を利用する”Argo CDを使用してアプリケーションのデプロイをしているなら、この方法を選択していましたが”前提”にも書いた通り、アプリケーションを helmfile でデプロイしているため Argo CD の案は却下しました。
.spec.ttlSecondsAfterFinishedを設定して Job が完了後、自動的に Job を削除する
Section titled “.spec.ttlSecondsAfterFinishedを設定して Job が完了後、自動的に Job を削除する”この方法では、Jobが完了した後に自動的に削除されますが、エラーが発生したPodさえも削除されてしまいます。
エラーが発生した場合、問題の原因を特定するためにJobを保持しておきたいと考えましたので、.spec.ttlSecondsAfterFinishedの設定は取りやめました。
Jobの.spec.ttlSecondsAfterFinishedフィールドを指定することにより、終了したJob(完了したもしくは失敗した)を自動的に削除するためにこの機能を使うことができます。 https://kubernetes.io/ja/docs/concepts/workloads/controllers/ttlafterfinished/
実際に動作確認してみます。
正常に終了する Job を作成し、ttlSecondsAfterFinished: 5 に設定します。
apiVersion: batch/v1kind: Jobmetadata: name: examplespec: ttlSecondsAfterFinished: 5 backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - echo "hoge" restartPolicy: NeverJob 完了後、一定の時間経って削除されていることがわかります。
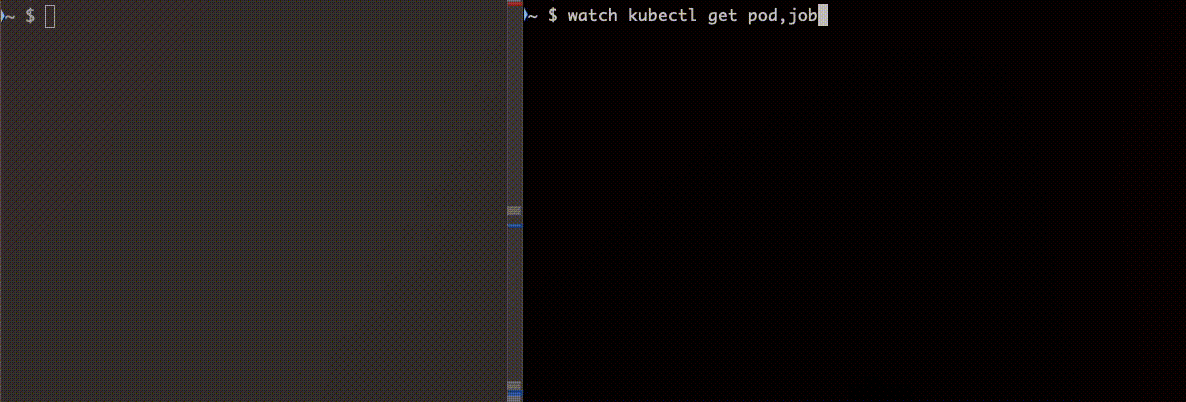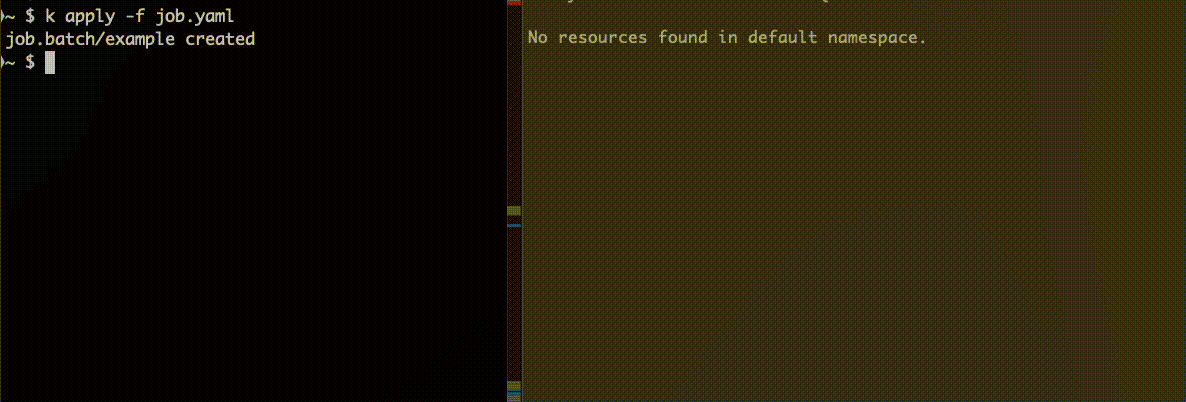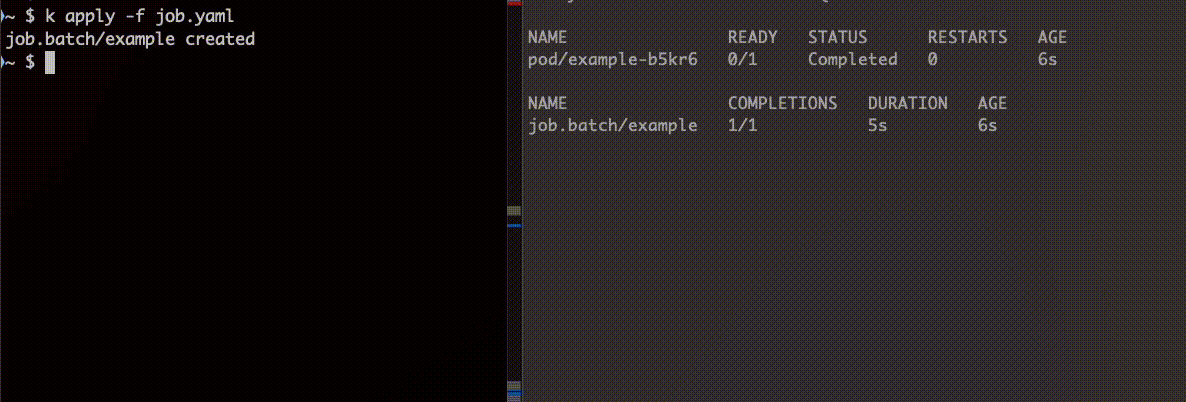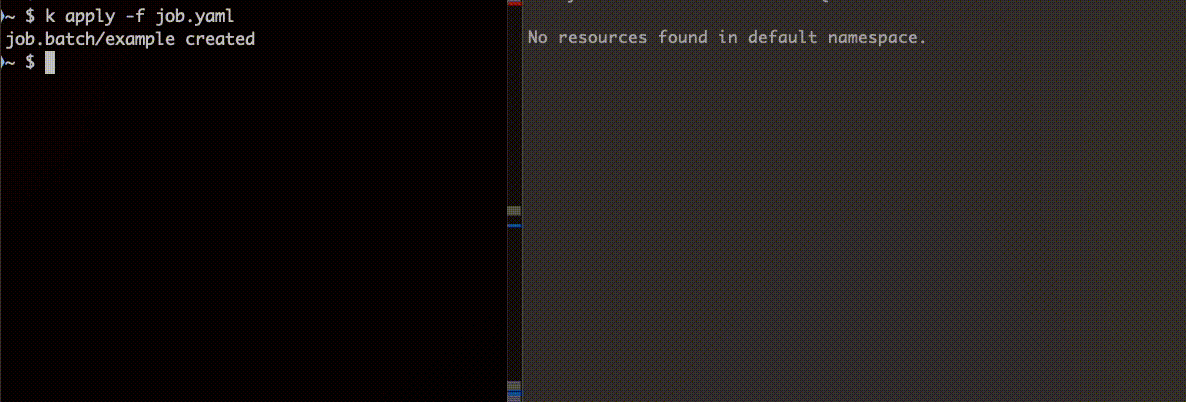
次にエラーになる Job を作成し挙動を確認します。
apiVersion: batch/v1kind: Jobmetadata: name: examplespec: ttlSecondsAfterFinished: 5 backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - echo "hoge" && exit 1 restartPolicy: Never
helm の hook を利用する
Section titled “helm の hook を利用する”hook の仕組みを使うことで、アプリケーションのデプロイ前に Job を実行できそうです。さらに helmfile を使ってデプロイをしているので、相性が良さそうです。
helm の hook も動作確認してみます。先ほど使用した job.yaml を templates ディレクトリ配下にコピペします。
$ helm create exampleCreating example$ rm -rf example/charts$ rm -rf example/templates/tests$ rm -rf example/templates/*.yaml$ touch example/templates/job.yaml
# 先ほど使用した job.yaml をコピぺする
$ helm template example---# Source: example/templates/job.yamlapiVersion: batch/v1kind: Jobmetadata: name: examplespec: ttlSecondsAfterFinished: 5 backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - echo "hoge" restartPolicy: Neverhook を追記します。
apiVersion: batch/v1kind: Jobmetadata: name: example annotations: "helm.sh/hook": pre-install,pre-upgrade "helm.sh/hook-weight": "1" "helm.sh/hook-delete-policy": hook-succeededspec:- ttlSecondsAfterFinished: 5 backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - echo "hoge" restartPolicy: Neverhelm install で Job をデプロイします。
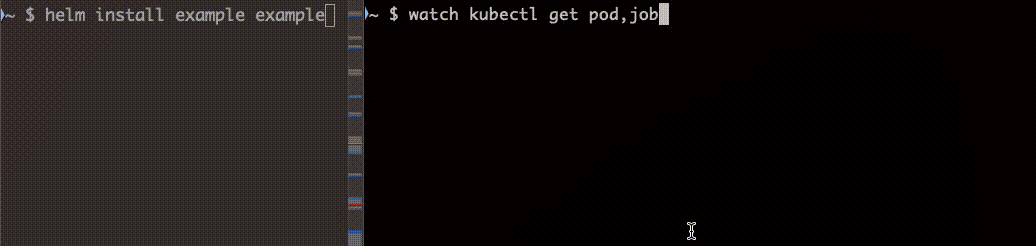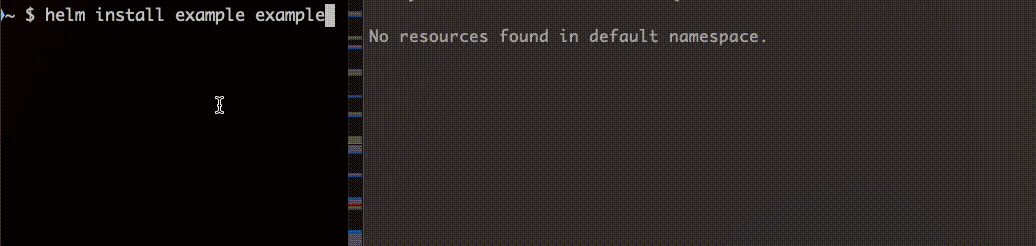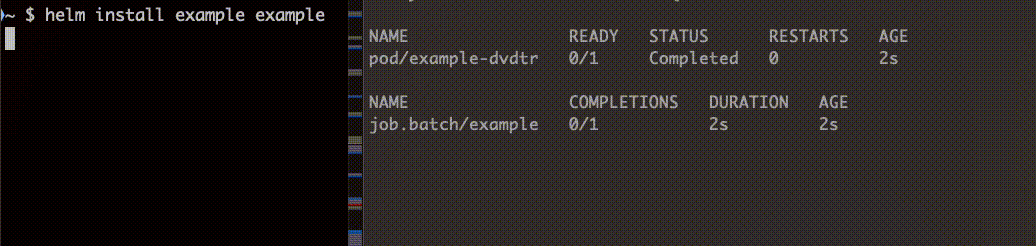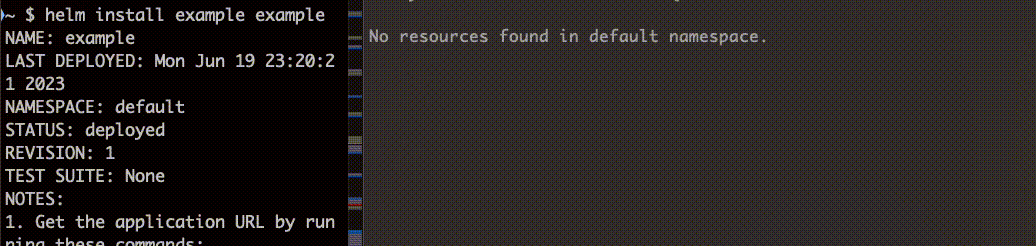
続いて helm upgrade で更新します。
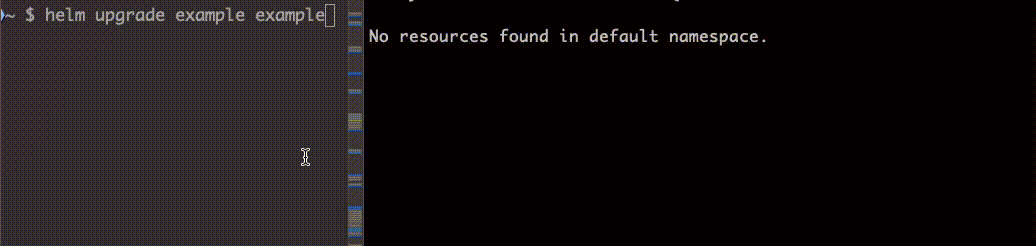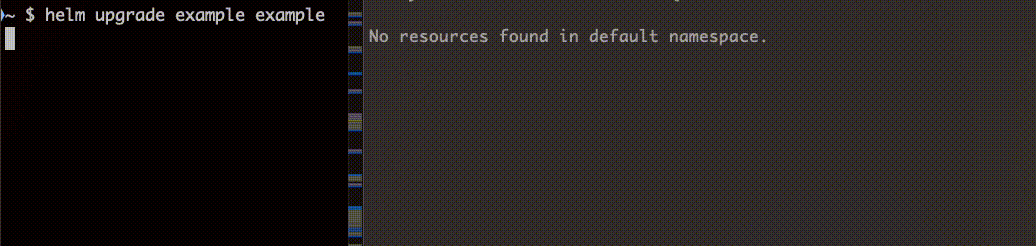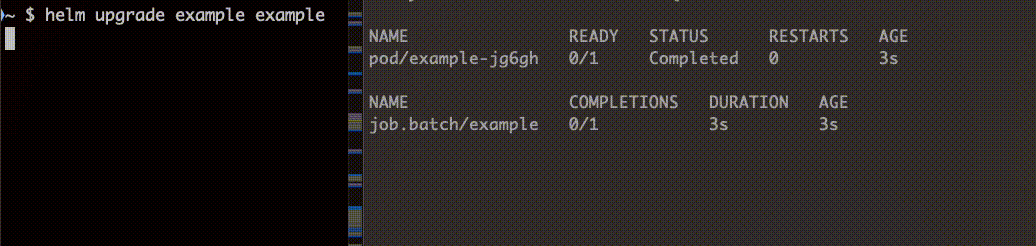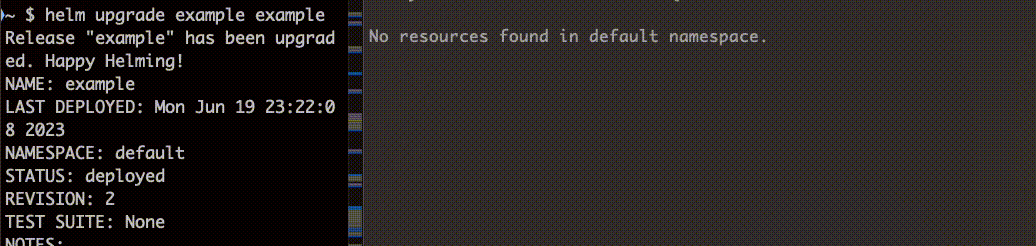
install、upgrade どちらの場合も Job 完了後に削除されていることがわかります。
今度は、エラーで失敗する Job をデプロイします。
apiVersion: batch/v1kind: Jobmetadata: name: example annotations: "helm.sh/hook": pre-install,pre-upgrade "helm.sh/hook-weight": "1" "helm.sh/hook-delete-policy": hook-succeededspec: backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - echo "hoge" && exit 1 restartPolicy: Neverエラーで Job が失敗した場合は helm コマンドの実行に失敗します。
さらに "helm.sh/hook-delete-policy": hook-succeeded を annotations に設定していたおかげでエラーになった後は Job が残りました。これで実際に失敗したとき原因調査できそうです。
エラーになった Job が不要になった場合は kubectl delete job <job名> で削除します。
最後に Job が完了してから Deployment が作成されることを確認します。
Job のコマンドを sleep にして挙動をわかりやすくします。
helm template
$ helm template example example---apiVersion: apps/v1kind: Deploymentmetadata: name: example-app labels: helm.sh/chart: example-0.1.0 app.kubernetes.io/name: example app.kubernetes.io/instance: example app.kubernetes.io/version: "1.16.0" app.kubernetes.io/managed-by: Helmspec: replicas: 1 selector: matchLabels: app.kubernetes.io/name: example app.kubernetes.io/instance: example template: metadata: labels: app.kubernetes.io/name: example app.kubernetes.io/instance: example spec: serviceAccountName: example securityContext: {} containers: - name: example securityContext: {} image: "nginx:1.16.0" imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 protocol: TCP livenessProbe: httpGet: path: / port: http readinessProbe: httpGet: path: / port: http resources: {}---# Source: example/templates/job.yamlapiVersion: batch/v1kind: Jobmetadata: name: example annotations: "helm.sh/hook": pre-install,pre-upgrade "helm.sh/hook-weight": "1" "helm.sh/hook-delete-policy": hook-succeededspec: backoffLimit: 1 template: spec: containers: - name: alpine image: alpine:latest command: ["sh"] args: - -c - sleep 5 restartPolicy: NeverJob の実行、削除、Deployment 作成、の順に実行されていることが確認できました。
マイグレーション完了後にアプリケーションのデプロイを行う順序を実現できる、かつ組織で使っているデプロイ方法と相性が良いので、最終的に helm の hook を使用することに決定しました。
Kubernetesとデータベースで実行しているアプリケーションのデータベースマイグレーション方法について考えてみました。
今回採用しなかった方法も要件や組織の状態によっては最適解になる可能性はあると思っているので、参考になれば幸いです。